
There’s a new economic force at work in the machine learning revolution that is capable of generating increasing returns to scale, much as network effects did in the internet revolution.
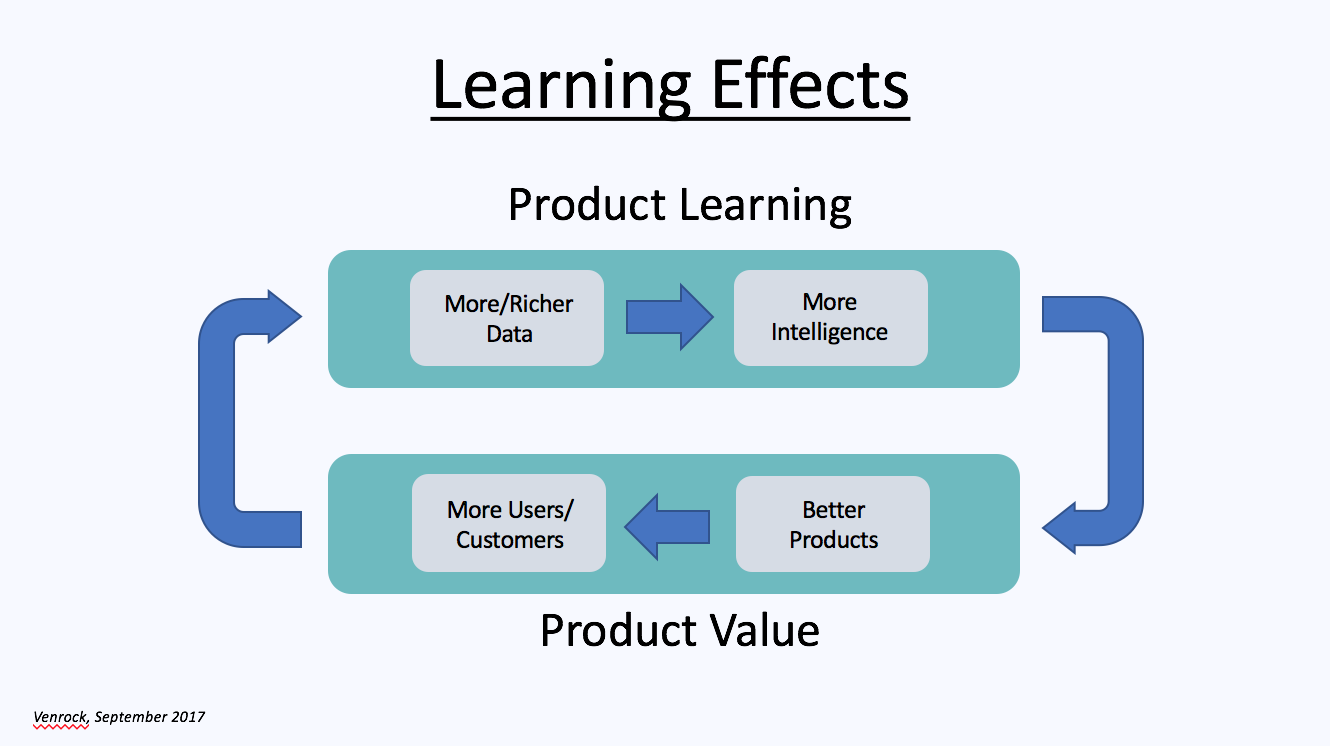
This force is automated learning, and its business impact comes in the form of learning effects: the more a product learns, the more valuable it becomes.
Learning effects have the potential to generate enormous economic value, as network effects do, if companies are able to close this loop and make it self-reinforcing: that is, if their products learn more because they have become more valuable.
This happens when more valuable products attract more users or customers, who provide more and richer data of the kind that enables machine learning models to make these products more valuable still, which attracts more users or customers still, and so on, creating a self-perpetuating cycle.
Just as network effects determined who the biggest winners of the internet revolution were, learning effects will determine who the biggest winners of the machine learning revolution will be.
Because they enable increasing returns to scale, they will similarly give rise to a set of companies that become runaway leaders – that are capable of pulling away from their competitors and continuing to increase their leads over time.
Offline Origins
Like network effects, learning effects have always existed in the offline world but have become supercharged in the digital world. In the offline world, learning effects are transmitted through humans: as people learn how a product can become more valuable, they modify it accordingly. Human learning, however, is artisanal, and artisanal learning only scales so quickly.
What’s new and different in the machine learning era is that certain kinds of learning have become automated. Software can learn by itself with exposure to new data and become more valuable in the process. This is a big deal economically. It involves the unlocking of new source of economic value that was previously inaccessible.
A Vast New Power
Learning effects have taken off most significantly at large internet platforms given the immense amount of data they control and their aggressive investment in machine learning to accelerate product innovation: Google in search, ads, photos, translate and Waze; Facebook in search, ads and newsfeed; and Amazon in search, ads, product recommendations and Alexa, to name just a subset for each. These companies recognize that machine learning has granted them a vast new power, and they are eager to take maximum advantage of it.
Perhaps the best pure-play example of the power of learning effects is Tesla, which began as an electric car company but was able to deploy machine learning to extraordinary effect across its fleet to become the category leader in autonomous driving. Tesla’s autonomous driving capabilities make its cars more valuable, which attracts more customers and data, which enables it to improve these capabilities further and attract even more customers, and so on. As a result of its learning effects, Tesla’s rate of innovation and value creation in the autonomous driving area have dwarfed what its competitors have been capable of.
Engineered Growth
Network effects and learning effects generate growth in different ways. Network effects tend to generate growth organically through a kind of gravitational accretion, as individual consumers and businesses pursuing their own self-interest decide to join the largest and most valuable networks, making them larger and more valuable still.
Learning effects similarly benefit from consumers and businesses pursuing their own self-interest to purchase the best products, but they are less the result of gravitational accretion than of finely tuned technology and product development efforts that require constant intervention and recalibration in order to tie together data, intelligence, product innovation and user/customer growth.
As a result, even though learning effects are partially the product of automated learning, they are by no means automatic. The data generated from new customers must be of the right kind and of sufficient volume to enable new learning. This learning must be optimized effectively enough to create new product value. And this value must be strong enough and productized well enough to attract more customers. Any break in this chain means there is no self-reinforcing cycle and hence no learning effects.
Runaway Leaders
Perhaps the most interesting question about learning effects is what are the conditions that make them strong enough to create runaway leaders, as these are the companies that tend to create the vast bulk of enterprise value in the technology startup world.
Learning effects don’t always produce runaway leaders. Just because one company has a head start in learning doesn’t mean other companies can’t acquire more or better data or learn more efficiently from similar data to catch up with them and eventually bypass them. It’s an interesting question today, for example, if Tesla is pulling away from the pack in autonomous driving, or if others will catch up in the years ahead.
In order for learning effects to produce runaway leaders, a company must secure a definitive advantage over its competitors in one of the component areas of learning effects – data, intelligence, product innovation or user/customer growth – and leverage this into advantages in the others, such that the company can acquire data, learn, innovate and grow not only more rapidly than its competitors do, but more rapidly than they can.
As with learning effects generally, there is nothing automatic about tying these advantages together. It requires excellent execution.
Typically a company is able to jumpstart this cycle by developing a significant data advantage over its competitors. It then must translate this data advantage into an intelligence advantage as measured by the capabilities of its machine learning models, which requires that its models be as or more efficient than those of its competitors. This intelligence advantage must then tie to a product innovation advantage that is directly correlated with a user or customer acquisition advantage and ultimately with an advantage in the size of its user or customer base. Enough customers have to want to buy Teslas, in other words, because of their autonomous driving capabilities vs. because it’s an electric or cool-looking car, as that doesn’t create a strong enough self-reinforcing cycle. Finally, this user or customer base advantage must enhance the company’s data advantage in the right way to generate additional learning.
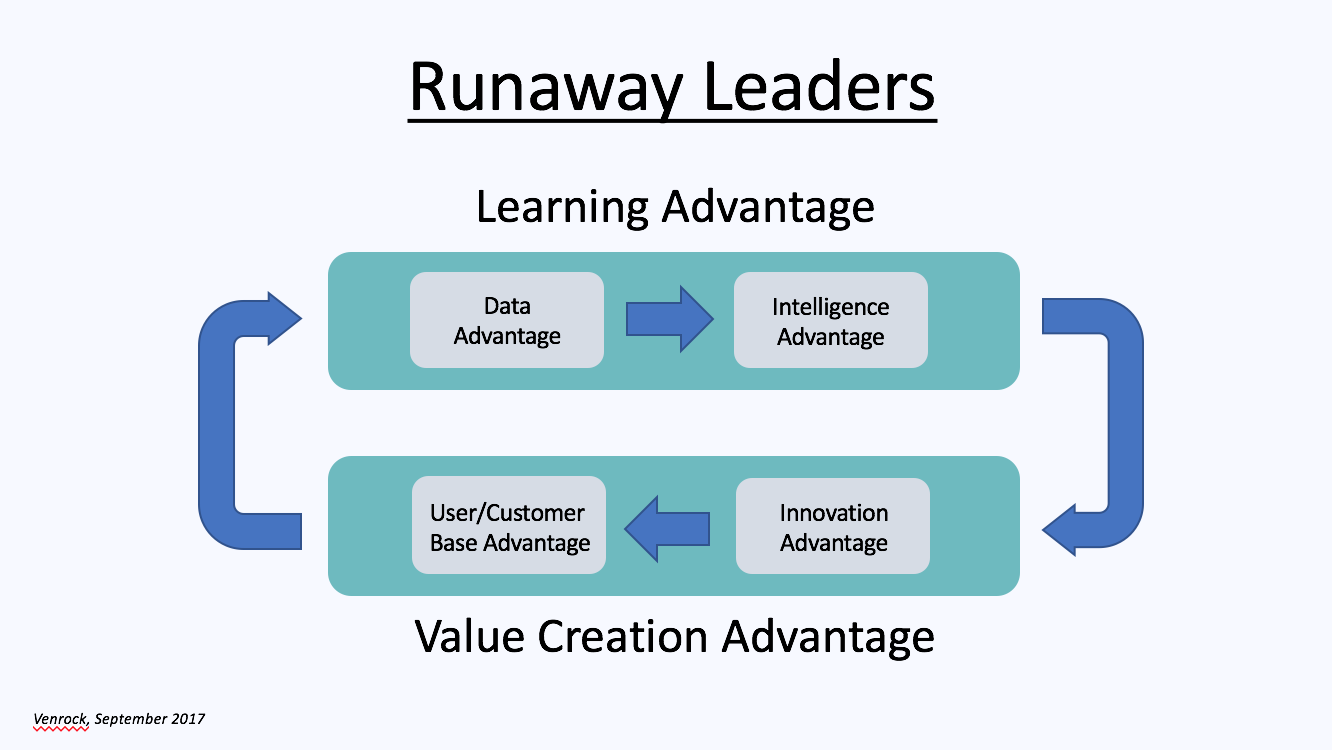
Generally the narrower the scope of a product and the greater the degree to which machine learning drives its value, the easier it is to tie these advantages together to create a runaway leader.
Wherever it is possible to tie these advantages together, there will likely be ferocious competition, as with network effects, for startups to get an initial head start in competing for scale to achieve escape velocity and become runaway leaders given the huge premium on winning. The early bird that capitalizes on its head start generally gets all the worms. Other birds need to bootstrap alternative advantages in the form of more efficient learning engines or access to large and differentiated datasets in order to have a chance.
Learning Curves: Long, Steep and Perpetual
In order for runaway leaders to be able to maintain their leads over time, there’s an important additional requirement, which is that the learning curves for their products must be long enough and steep enough to enable them to provide increasing product value for an extended period. If the learning curves for their products are short or top off quickly, early leaders will max out on them while they still have viable competitors, and these competitors will be able to catch up. If the learning curves are long and steep, on the other hand, these companies will have sufficient runway to break away from their competitors and maintain their leads over time.
Certain products – particularly those built on highly dynamic datasets – may have perpetual learning curves such that in a rapidly changing world, they can always be meaningfully improved. It’s around these kinds of products that the most valuable runaway leaders will likely develop. Potential examples include search, semantic engines, adaptive autonomous systems and applications requiring a comprehensive real-time understanding of the world.
The Interaction of Learning Effects and Network Effects
Network effects almost always create the opportunity for learning effects, as they involve the generation of ever more data in the form of new network members and interactions. Companies must invest in machine learning to create these learning effects, and they may or may not be successful. They may fail to generate meaningful learning, or they may generate meaningful learning but not learning effects if this learning does not result in more valuable products that lead to the continual acquisition of new data for additional learning.
Conversely, learning effects can create network effects. Tesla, for example, did not benefit from network effects when it was just an electric car company and was not yet focused on autonomous driving. However, once the company outfitted its cars with information sensors to develop autonomous driving capabilities through machine learning, it suddenly began to benefit from network effects: each Tesla became more valuable the larger the fleet became.
Importantly, however, when learning effects create network effects, these network effects do not exist independently of them. They are in effect an expression of the learning effects: learning just happens to take place through a network. If Tesla turned off its machine learning, its network effects would cease to exist.
The reverse, however, is not true. Network effects can give rise to learning effects that can exist independently of them. Facebook’s core network effect of people wanting to be part of the same social network that their friends are, for example, generates lots of new data that machine learning models can learn from. One area where Facebook has invested significantly in machine learning and succeeded in generating learning effects is improving the relevance of its newsfeed. Newsfeed relevance is a different kind of value than the core value around which the company’s network effects are based, although the two clearly reinforce each other. If Facebook stopped growing its user baser, it could continue to generate increasing value by improving the relevance of its newsfeed through these learning effects.
Since network effects and learning effects are both functions of customer value, whenever they exist side by side in a product, they always reinforce each other, as each makes the product more valuable in a way that attracts more customers and data.
The most formidable kinds of runaway leaders that tend most strongly toward natural monopoly – Facebook and Google are excellent examples – are those that benefit from network effects and learning effects working in tandem, as their mutual reinforcement means these companies run away from the pack much faster and are generally impossible to catch, provided they also benefit from perpetual learning curves.
Startups vs. Incumbents
Incumbent internet platforms have unsurprisingly been the big winners of the machine learning revolution to date because of their vast data assets and their significant investment in this new technology. Their early dominance has led skeptics to wonder if machine learning is a game that startups can win at all given their relative data disadvantages.
There are huge new datasets and data-rich applications created every day, however, in domains where these and other platforms have little or no presence, which provide an abundance of new opportunities for startups.
In addition, there are many large datasets sitting in organizations that startups are best suited to access because they are better able to provide these organizations with innovative applications to take advantage of them.
And although startups make lack the early edge in data, they always have the advantages of focus and adaptability. Where I believe these advantages will make the biggest difference in machine learning is that machine learning applications are engines, and startups have the ability to build and tune these engines most precisely to maximize learning effects. They have the ability not only to maximize the amount of learning and hence value they create from new data, but to complete this loop and maximize the amount of data in the form of new customers they create from new learning.
Only by constantly tightening and amplifying these loops can companies grow rapidly from learning effects and hope to achieve escape velocity to become runaway leaders. As a general rule, startups tend to be better at this than incumbents.
This article was originally published on Techcrunch