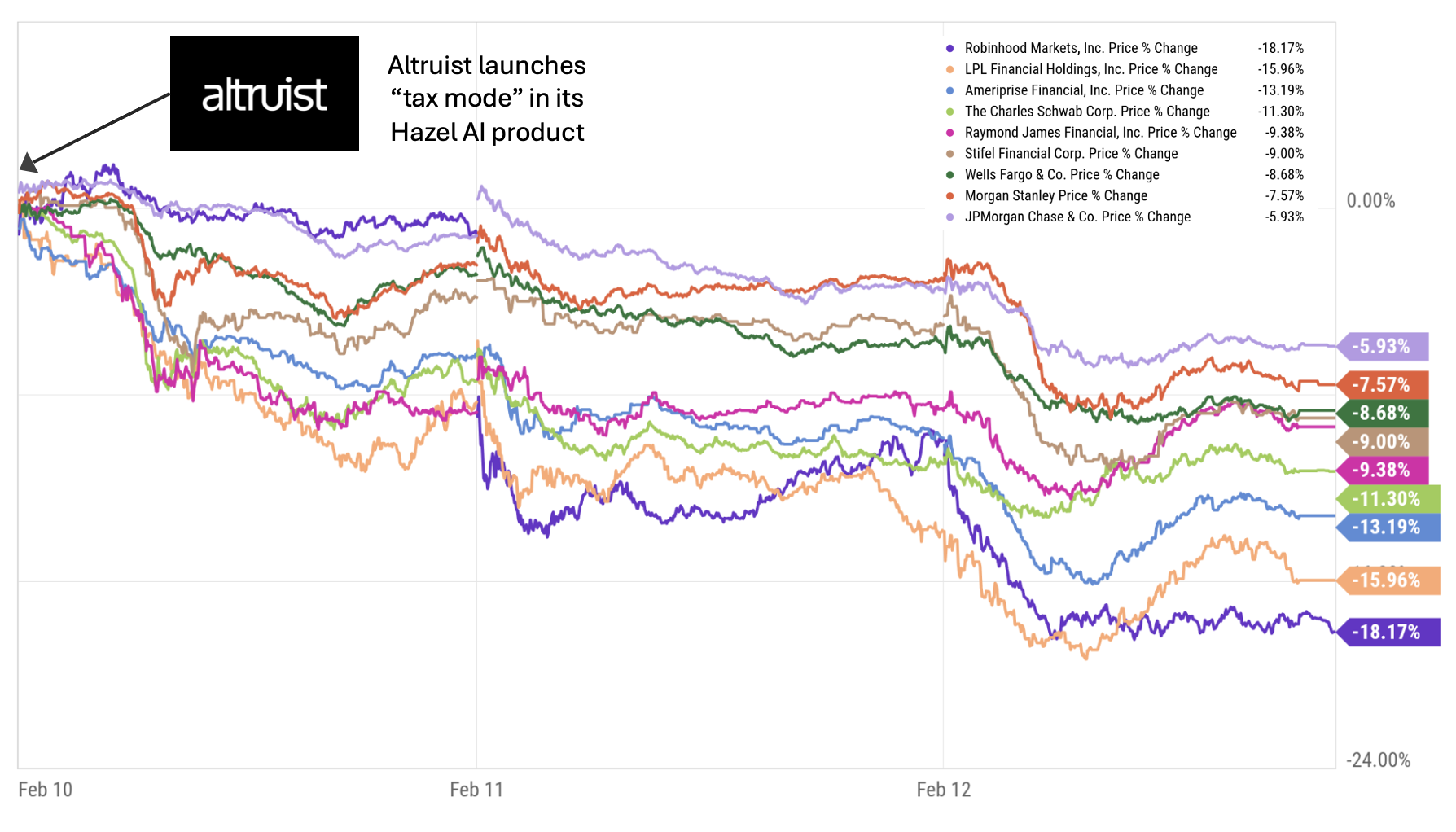
On February 10, Altruist announced a new AI-powered capability called “tax mode” in its Hazel AI product. Public wealth management stocks dropped precipitously, losing $150 billion in value over the next day and a half and leveling off at a total loss of $130 billion by Feb 12. It was wealth management’s DeepSeek moment.
What happened? What is Hazel’s “tax mode”? And what does this episode tell us about how markets are thinking about AI’s impact on wealth management?
What Makes Hazel Different
AI in wealth management is not new. Over the past 18 months, we’ve seen the rise of AI note takers and workflow assistants tailored for financial advisors—companies like Jump and Zocks. These tools sit on top of meetings, generate summaries, pre-fill CRM entries, draft follow-up emails, and help with compliance documentation. They are useful, but not transformational.
Hazel is different for one reason that matters enormously: it is integrated directly into the custodial system and has access to custodial data. Note takers such as Jump and Zocks operate at the “conversation layer.” They hear what the client says. They can summarize goals and generate follow-ups. But they do not have direct, structured, authoritative access to portfolio-level, tax-lot-level, account-level custody data. That means they can’t do things like calculate real-time embedded gains, model tax-loss harvesting across accounts, optimize asset location dynamically and identify wash sale conflicts across household accounts. Hazel can.
Because Altruist is both the advisor’s platform and the custodian, Hazel’s “tax mode” can query the actual ledger of record. It can look at every lot, every gain, every loss, every account registration. It can move from conversation to action without manual reconciliation between systems. That’s a fundamentally different starting point than an AI tool that only listens to a Zoom call.
Why Tax Is the Most Valuable—and Most Difficult to Scale—Service in Wealth Management
In wealth management, advisors often say that tax alpha is the most tangible value they create. Investment returns are partly market-driven. Behavioral coaching is real but hard to quantify. Planning is episodic. But tax management—done correctly—can produce measurable, after-tax outperformance year after year.
And yet, tax optimization is one of the hardest services to scale. Why? Because it involves painstaking research and analysis involving cross-account coordination, household-level modeling, timing sensitivity, compliance and documentation, and because it requires advisor judgment.
Today, many advisors still rely on spreadsheets, manual analysis and fragmented tools to deliver tax insights. Even with modern rebalancing software, true household-level, dynamic, AI-driven tax optimization remains complex and labor-intensive.
Hazel’s “tax mode” attacks exactly this bottleneck. It can instantly surface tax-loss harvesting opportunities, simulate gain-offset strategies, optimize asset location across taxable and tax-deferred accounts and draft client-ready explanations in seconds.
In other words, it converts high-skill, low-scale labor into software leverage. That’s why the market reacted.
Why Existing Custodians Are at a Structural Disadvantage
It would be easy to assume that large custodians like Charles Schwab or Fidelity could simply replicate Hazel’s functionality. But that assumption overlooks something structural: legacy custody platforms are not modern wealth infrastructure. Most large custodians operate on decades-old systems layered with multiple acquired platforms, patchwork integrations, batch-processing architectures, rigid data schemas and complex internal permissioning systems. These systems were not built for real-time AI integration. They were built for record-keeping, trade settlement, regulatory reporting and operational stability.
To integrate a true AI tax engine at the core of custody requires clean and normalized data architecture, real-time API access, flexible permissions and modular service design. Altruist, as a modern fintech custodian built in the cloud era, has the architectural advantage. Its custody stack was built with modern technology, APIs and data-layer accessibility in mind. By contrast, retrofitting AI deeply into a legacy custody core is more like open-heart surgery than adding a feature.
This doesn’t mean Schwab or Fidelity won’t respond. It means the speed and depth of response are structurally constrained. Markets are extremely sensitive to that distinction.
Why the Market Reaction Was So Large
The selloff was not just about tax-loss harvesting software. It was about the potential repricing of advisor productivity, platform differentiation, margin structures, custody defensibility and client acquisition economics.
If AI tools embedded in modern custodians materially increase advisor productivity, several second-order effects follow:
- Advisors may consolidate onto AI-enabled platforms
- Smaller RIAs could scale faster with fewer staff
- Tax alpha becomes more standardized
- Client expectations rise
- Platform switching becomes more attractive
For firms that earn basis points on trillions of AUM, even a small change in retention, growth, or pricing power compounds dramatically.
Markets price optionality. And they price competitive displacement risk even more aggressively.
One Interpretation: How Much Value Could AI Create?
One way to interpret the $130 billion market drop is not as a measure of value destroyed, but as a real-time, market-implied estimate of potential value transfer in the industry.
Consider:
- The U.S. wealth management industry oversees roughly $30–40 trillion in advised assets
- Advisors typically charge 50–100 basis points
- Even a 5–10 basis point shift in value capture (through better tax optimization, other new AI capabilities and competitive pressure) equates to tens of billions annually
Who captures this value? Advisors themselves seem well-positioned to capture some of it. If AI-enabled tax optimization allows them to deliver 20–40 basis points of after-tax alpha, or reduce staffing costs by 20–30%, or improve client retention by even 1–2%, the cumulative value creation across the industry could be significant.
Consumers themselves will benefit greatly from faster, more automated and more rigorous tax optimization and other AI capabilities to come. And some advisors offering leaner, more responsive organizations may choose to share some of these gains in the form of lower fees.
One significant set of beneficiaries of this value transfer will be providers of powerful new AI capabilities that are not easily replicated by others. Altruist is off to a strong start in this category as a high-tech, full-stack custodian with a growing suite of AI-enabled capabilities embedded in its Hazel platform. It has already announced additional Hazel modules for financial planning and compliance support to be released in the quarters ahead, and many more will follow.
At Venrock we have invested in a variety of AI-enabled technology companies in wealth management seeking to provide similarly high-value products and services that cannot be easily replicated. In addition to Altruist, these include FINNY (an AI-enabled prospecting platform for advisors with its own data infrastructure), Moment (a fixed income trading and portfolio management platform with its own data and execution infrastructure), Vanilla (AI-enabled estate planning software) and two additional companies that will come out of stealth mode shortly.
The Big Picture
The wealth management industry has historically been insulated from software-style disruption because of some of the core characteristics of advisory work: relationships matter, regulation slows change and switching costs are real.
AI doesn’t eliminate these factors. But it does amplify the advantages of modern infrastructure. Hazel’s significance is not just that it uses AI. It is that it uses AI at the custodial data layer, enabling tax optimization—and ultimately additional capabilities—to be delivered programmatically. That’s why other AI note takers cannot replicate it. That’s why legacy custodians face integration challenges. And that’s why markets erased over $130 billion in market value in days.
The episode suggests something larger: AI’s value in wealth management will not come from replacing advisors, but from radically increasing their leverage. And in a trillion-dollar industry built on basis points and operating leverage, even modest improvements in productivity, tax alpha, and platform differentiation can justify very large valuation swings.
The market reaction may ultimately prove exaggerated. But it revealed something unmistakable: investors believe AI can reshape the economics of wealth management at scale. And when the ledger of record meets the language model, the consequences ripple far beyond a single product announcement.